최근 ECS를 도입하면서 Rolling Deploy 를 적용했다. 이전에는 EC2인스턴스마다 방문하면서 배포를 했다면 이제는 새로운 Fargate기반 태스크가 생성되면서 기존 태스크는 없애는 방식으로 배포된다.
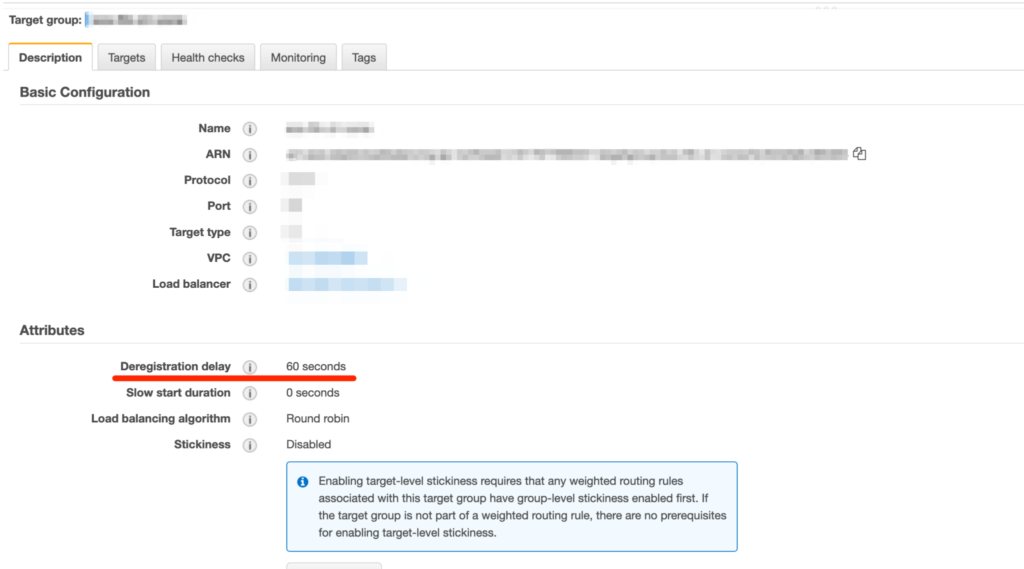
테스트를 진행하다보니 ALB Target Group에 등록된 아이템이 Draining에 걸리는 시간이 긴 것이 눈에 들어왔다. 기본값으로 이 값은 300초가 주어지기 때문에 트래픽이 많지 않거나 커넥션을 오래 유지할 필요가 없다면 이 시간만큼 Fargate인스턴스를 더 사용하는 셈이다.
타겟그룹의 Draining에 걸리는 시간은 “Deregistration delay”항목에서 수정할 수 있다.
오랜만에 Aurora MySQL의 최대 접속수를 다시 지정했다. 개발용도의 데이터베이스는 사용량은 작지만 여러 프로젝트들이 connection pool 을 생성하니 기본 정의값보다 올려서 사용하는 경우가 종종있다. max_connections를 다시 지정한 파라미터 그룹으로 교체하면 된다. 이건 TIL이라 할 것도 없다.
하지만 글로 남기는건 10분이면 될 일을 1시간이나 헤맸기 때문.
클러스터 파라미터그룹과 인스턴스 파라미터 그룹 양쪽에 max_connections가 있다.
파라미터 수정 후 apply immediately로는 동작하지 않아서 reboot 후 적용되었다.
변경된 수치는 다음쿼리로 확인가능하다.
mysql> select @@max_connections;
+-------------------+
| @@max_connections |
+-------------------+
| 300 |
+-------------------+
1 row in set (0.00 sec)
BigQuery의 테이블스키마는 생성할때 UI가 꽤 불편한 편이다. 그래서 텍스트로 편집 옵션이 있기도 하지만 타이핑하기 좋지 않은 신택스를 가지고 있어서 CSV업로드로 자동생성하는 편이 개인적으로는 가장 편했다.
CSV 파일 업로드는 10MB까지만, 그 이상은 Cloud Storage 등에서 가져와야 한다.
CSV가 다룰 수 있는 데이터 타입에는 한계가 있다. 예를들어 날짜시간 등을 사용하고자 하면 메뉴얼의 Limitation부분을 잘 읽어보고 활용해야한다.
테이블 변경은 쿼리결과 저장 기능으로
BigQuery는 ALTER TABLE 문을 지원하지 않는다. 따라서 잘못만들면 테이블을 다시 만들어야 한다. 이때 테이블로 결과를 보내는 쿼리결과 저장기능을 활용할 수 있다. 다시말해 SELECT * FROM 식으로 조회한 결과를 테이블로 보내는데, 자기테이블을 덮어씌우는 방법을 사용한다. 이때 AS를 사용해 리네임을, CAST 함수를 사용해 컬럼의 타입을 변경할 수 있다.
물론 이에 따른 데이터 조회 / 쓰기 비용은 발생한다.
레코드는 피하자
except() 함수 등을 활용할 때 레코드는 통째로 처리되어서 불편할때가 있다. 예를들어 http 응답을 response.status, response.body 등으로 담았다고 치자. response.body 는 덩치가 크니까 가져오지 말고 response.status만 원하면 SELECT * except(response.body) 는 동작하지 않는다. 원하는 필드명을 하나씩 명시해야 한다. BigQuery에서 필드 = 돈이다.